/** * Returns a hash code for this {@code Integer}. * * @return a hash code value for this object, equal to the * primitive {@code int} value represented by this * {@code Integer} object. */ @Override public int hashCode() { return Integer.hashCode(value); } /** * Returns a hash code for a {@code int} value; compatible with * {@code Integer.hashCode()}. * * @param value the value to hash * @since 1.8 * * @return a hash code value for a {@code int} value. */ public static int hashCode(int value) { return value; }
/** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ static final int MAXIMUM_CAPACITY = 1 << 30; /** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
public static void main(String[] args) { // TODO Auto-generated method stub int a=3; //定义一个基本数据类型的变量a赋值3 Integer b=a; //b是Integer 类定义的对象,直接用int 类型的a赋值 System.out.println(b); //打印结果为3 }
上面代码中的Integer b = a;就是我们所说的自动装箱的过程,上面代码在执行的时候调用了Integer.valueOf(int i)方法简化后的代码:
public static Integer valueOf(int i) { if (i >= -128 && i <= 127) return IntegerCache.cache[i + 127]; //如果i的值大于-128小于127则返回一个缓冲区中的一个Integer对象 return new Integer(i); //否则返回 new 一个Integer 对象 }
可以看到Integer.valueOf(a)其实是返回了一个Integer的对象。因此由于自动装箱的存在Integer b = a这段代码是没有问题的,并且我们可以简化的来这样写:Integer b = 3;
public static Integer valueOf(int i) { if (i >= -128 && i <= 127) return IntegerCache.cache[i + 127]; //如果i的值大于-128小于127则返回一个缓冲区中的一个Integer对象 return new Integer(i); //否则返回 new 一个Integer 对象 }
上面的代码中:IntegerCache.cache[i + 127]; 表示狠眼生,继续看代码:
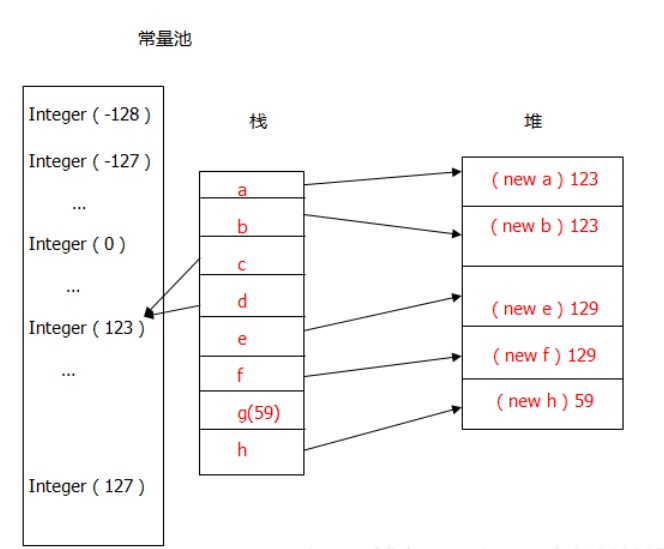
private static class IntegerCache { static final Integer cache[]; //定义一个Integer类型的数组且数组不可变 static { //利用静态代码块对数组进行初始化。 cache = new Integer[256]; int j = -128; for(int k = 0; k < cache.length; k++) cache[k] = new Integer(j++); } //cache[]原来是一个Integer 类型的数组(也可以称为常量池),value 从-128到127, public static Integer valueOf(int i) { if (i >=-128 && i <= 127) return IntegerCache.cache[i + (-IntegerCache.low)]; //如果装箱时值在-128到127之间,之间返回常量池中的已经初始化后的Integer对象。 return new Integer(i); //否则返回一个新的对象。 } }
原来IntegerCache类在初始化的时候,生成了一个大小为256的integer类型的常量池,并且integer.val的值从-128~127,当我们运行Integer c = a(临时做的一个小栗子哈)的时候,如果-128 <= a <= 127,就不会再生成新的integer对象。于是我们第二部分的c和d指向的是同一个对象,所以比较的时候是相等的,所以我们输出true。
public class Person { //定义一个move()方法 public void move(){ System.out.println("正在执行move()方法"); } //定义一个eat()方法,eat()方法需要借助move()方法 public void eat(){ Person p = new Person(); p.move(); System.out.println("正在执行eat()方法"); } public static void main(String[] args) { //创建Person对象 Person p = new Person(); //调用Person的eat()方法 p.eat(); } } // 代码来源于:https://zhuanlan.zhihu.com/p/62779357
//定义一个eat()方法,eat()方法需要借助move()方法 public void eat(){ move(); System.out.println("正在执行eat()方法"); }
整体代码可以如下
package cn.mr8god.example; /** * @author Mr8god * @date 2020/4/14 * @time 16:09 */ public class Person { public void move(){ System.out.println("正在执行move()方法"); } public void eat(){ move(); System.out.println("正在执行eat()方法"); } public static void main(String[] args) { Person p = new Person(); p.eat(); } }
package cn.mr8god.example; /** * @author Mr8god * @date 2020/4/14 * @time 17:05 */ public class Person { public int age; public Person(){ int age = 0; this.age = 3; } public static void main(String[] args) { System.out.println(new Person().age); } }
public class Person { public int age; public Person grow() { age ++; return this; } public static void main(String[] args) { Person p = new Person(); //可以连续调用同一个方法 p.grow().grow().grow(); System.out.println("p对象的age的值是:"+p.age); } }
#include <iostream> const int ArSize = 8; int sums(int arr[], int n); int main() { using namespace std; int counts[ArSize] = { 1, 2, 4, 8, 16, 32, 64,128}; int sum = sums(counts, ArSize); cout << "Total counts: " << sum << "\n"; return 0; } int sums(int arr[], int n){ int total = 0; for(int i = 0; i < n; i++) total = total + arr[i]; return total; }
#include <iostream> const int ArSize = 8; int sums(const int * begin, const int * end); int main(){ using namespace std; int things[ArSize] = {1, 2, 4, 8, 16, 32, 64, 128}; int sum = sums(things, things + ArSize); cout << "Total things eaten: " << sum << endl; sum = sums(things, things + 3); cout << "First three people buy " << sum << " things.\n"; sum = sums(things + 4, things + 8); cout << "Last four people buy " << sum << " things.\n"; return 0; } int sums(const int * begin, const int * end){ const int * pt; int total = 0; for(pt = begin; pt != end; pt++) total += *pt; return total; }
#include <iostream> void simple(); int main(){ using namespace std; cout << "main() will call the simple() function:\n"; simple(); cout << "main() is finished with the simple() function.\n"; cin.get(); return 0; } void simple(){ using namespace std; cout << "I'm but a simple function.\n"; }
package cn.mr8god.refactoring; /** * @author Mr8god * @date 2020/4/12 * @time 00:14 */ public class Rental { private Movie _movie; private int _daysRented; public Rental(Movie movie, int daysRented){ _movie = movie; _daysRented = daysRented; } public int getDaysRented(){ return _daysRented; } public Movie getMovie(){ return _movie; } }
package cn.mr8god.refactoring; /** * @author Mr8god * @date 2020/4/12 * @time 00:01 */ public class Movie { public static final int CHILDRENS = 2; public static final int REGULAR = 0; public static final int NEW_RELEASE = 1; private String _title; private int _priceCode; public Movie(String title, int priceCode){ _title = title; _priceCode = priceCode; } public int getPriceCode(){ return _priceCode; } public void setPriceCode(int arg){ _priceCode = arg; } public String getTitle(){ return _title; } }
package cn.mr8god.refactoring; /** * @author Mr8god * @date 2020/4/12 * @time 00:01 */ public class Movie { public static final int CHILDRENS = 2; public static final int REGULAR = 0; public static final int NEW_RELEASE = 1; private String _title; private int _priceCode; public Movie(String title, int priceCode){ _title = title; _priceCode = priceCode; } public int getPriceCode(){ return _priceCode; } public void setPriceCode(int arg){ _priceCode = arg; } public String getTitle(){ return _title; } }