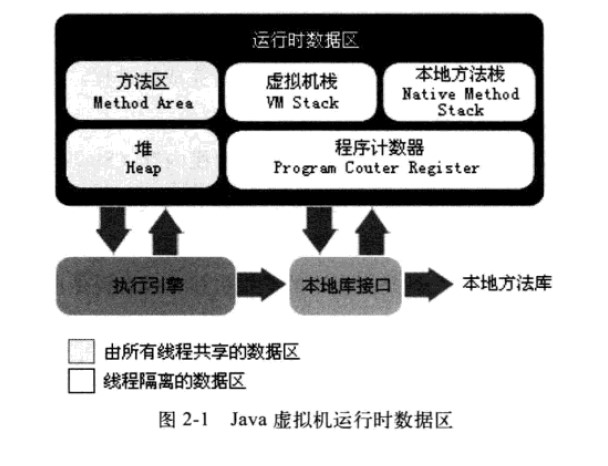
Java是一种面向对象编程(OOP)的语言。 掌握Java需要付出的代价就是,思考对象的时候,需要采用 形象思维(一种抽象思维),而不是程序化的思维。 特别是在尝试创建可重复使用(可再生) 的对象的时候,我们都会面临着一项痛苦的抉择。 事实上,正是由于这样的特性,很难有人能够设计出完美的东西,只有一些Java的编程专家才能编写出可以让大多数人使用的代码,而我江某人学习编程的目的就在于此,成为编程专家。
初章主要是描述了Java的多项设计思想,并从概念上解释面向对象的程序设计。
抽象概念的由来
抽象方法是怎么出现的呢?
起因是我们在解决实际问题的时候发现每一类问题都有其自己的特征。而我们在C或一切其他语言中学到的都只是根据一类问题设计一套方法来解决它。以至于当超出这个问题的时候,方法就会显得特别笨拙。 面向对象的程序设计就是在以上基础跨出一大步。我们利用一些概念去描述表达实际问题中的元素。我们利用“对象”这个概念建立起实际问题和方法之间的联系。如果一些问题在后期出现了更多的问题,我们就可以相应的在代码中加入其它对象 通过添加新的对象类型,程序可以灵活的进行调整。与特定的问题打配合。从而达到解决问题的目的。 毫无疑问,面向对象程序设计语言是一门灵活、强大的语言抽象方法。它允许我们根据问题来描述问题,而不是单纯地根据方案。
OOP面向对象程序设计的特征
通过上面讲述的这些特征,我们可以理解“纯粹”的面向对象程序设计方法是什么样子的: (1) 所有东西都是对象。可以将对象想象成一种新型变量;它保存着数据,但可要求它对它自身进行一些操作,比如说增加点方法,增加点变量。理论上来讲,我们可以从问题中找出所有概念性的东西,然后在我们的程序中将其表达为一个对象。
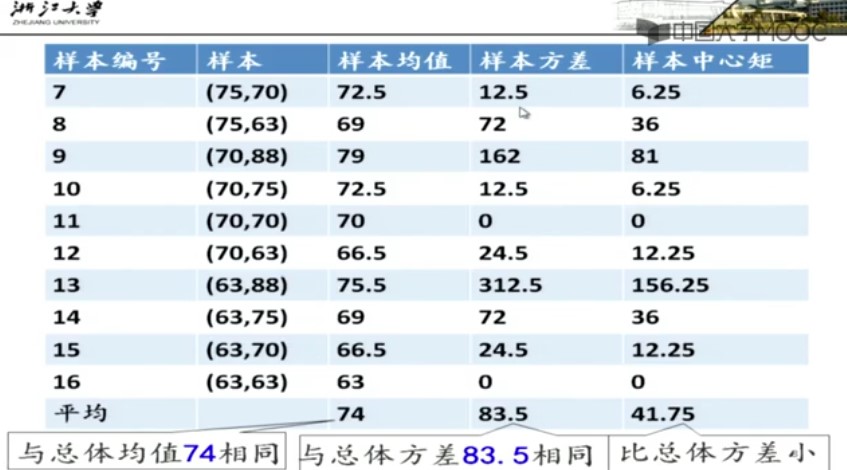
(2) 程序将会是一大堆对象的组合;通过对象与对象之间的消息传递(传参),各个对象都知道自己该干什么,不该干什么。为了向另外一个对象发出请求,就需要向那个对象发送消息。具体来讲,我们可以将消息想象为一个调用请求,它调用的是从属于目标对象的一个子例程或函数。
(3) 每个对象都有自己的存储空间,可以容纳其他对象。或者是通过封装现有对象,进而制造出新的对象。所以尽管先前我们讲的对象看起来很简单,其实在每一个程序中,这些概念都能上升到一个任意高的复杂程度。
(4) 每个对象都有一种类型。根据Java的基本语法,每个对象都是某一个“类”的一个“实例”。而不同类与类之间的区别是什么呢?我抽象地讲,是“能将什么消息发给它?”
(5) 同一类的所有对象都能接收相同的消息。举例子举例子,这边有圆(Circle)、形状(Shape)两个类。由于圆其实也是形状嘛,我可以这样说,圆(Circle)的一个对象也属于类型为形状(Shape)的一个对象,所以一个圆能够完全接收来自形状(Shape)的任意消息。这就意味着我们可以让程序代码统一指挥形状(Shape),令其自动控制所有符合形状(Shape)描述的对象,其中自然包括圆(Circle)类的那个对象。这一特性叫做对象的”可替换性“,是OOP最重要的概念之一。
对象的接口
上头我已经为大家引入了类与对象的概念,其实很好理解。类就相当于一样东西,比如说程序员就是一类。而对象呢,按照程序员类来说,这边的对象就是具体的一个程序员,比如说我江某人,就是一个程序员类的对象。
每一个对象都隶属于一个特定的“类”,那个类具有自己的通用特征与行为。
我们该如何让对象完成真正有用的工作呢?比如说让我江某人程序员对象完成一个C++的代码工作。我们可以在类中定义“接口”,对象的“类”就规定了它的接口形式。“类”和“接口”的等价或对应关系就是面向对象程序设计的基础。
下面来一个图解
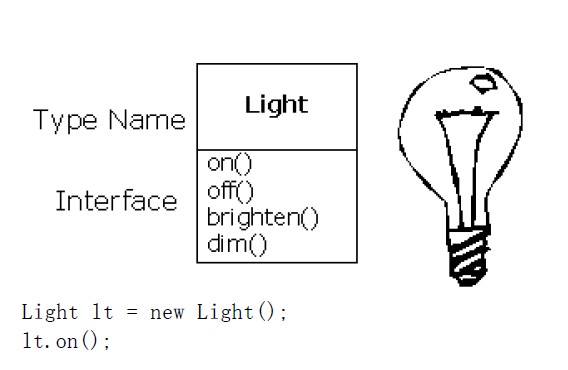
在上面这个图解中,,类的名字叫做Light,我们可以向Light对象发出的请求包括有打开(on)、关闭(off)、变得更明亮(brighten)、变得更黯淡(dim)。我们可以简单地声明一个名字(lt),我们为Light对象创建了一个“句柄”(就是名字,咱们对象的名字,在这边名字就叫做lt),这里边lt,也就是咱们的句柄,指向了刚刚新建的对象。然后我们用new关键字新建类型为Light的一个对象。再用等号将其赋值给句柄。
为了向对象发送一条消息,我们使用下面的格式来将句柄名、句点符号、和消息名称(on、off之类的)连接起来:
lt.on();
实现方案的隐藏
这部分我将谈谈我们为什么要隐藏我们的类成员,类中的方法
首先我想就程序员的分类来讲,目前使用面向对象程序设计语言的程序员主要是分为两类的,一类是类的创建者,一类是类的使用者。前者制造出了包含各种使用的类包,后者会用前者的类包,解决各种问题。
这个时候,我们就需要考虑一个问题了,类创建者创建的类包里不能所有东西都能被使用者调用呀。如果任何人都能使用一个类的所有成员,那么使用者就可以对那个类做出任何事情。即使是一些不能够给使用者使用的类内包含的一些成员。如若不能进行控制的话,就没有办法组织这一情况的发生。
为啥要控制类中成员的访问权限呢?
综上,我们有两方面的原因促使我们需要对类中成员的访问权限进行控制。 原因一:防止使用者程序员接触他们不该接触的东西——通常是一些内部数据类型的设计思想。若只是为了使用类包解决问题,用户只需要操作接口就行了,不需要明白这些信息。我们向用户提供的实际是一种服务。 原因二:允许类包设计人员修改内部结构,不用担心它对使用者程序员造成影响。假如我们(类设计程序员)最开始写了一个简单的类包,以便简化开发。以后又决定进行改写,使其更快地运行。若接口与实现方法早已经隔离开了,并分别受到保护,就可以放心做到这一点。
Java如何实现控制呢?
Java采用三个显式(明确)关键字以及一个隐式(暗示)关键字来设置类边界:public、private、protected 以及暗示性的friendly。若未明确指定其他关键字,则默认为后者。
解释这些关键字:
public(公共):意味着后续的定义,任何人均可使用。 private(私有):意味着除您自己、类型的创建者以及那个类型的内部函数成员之外,其他任何人都不能访问后续的定义信息。private在类创建者和类使用者之间竖起了一堵墙。若有人试图调用,便会在编译期报错。 friendly(友好的)涉及“包装”或“封装”(Package)的概念——即Java用来构建库的方法。若某样东西是“友好的”,意味着它只能在这个包装的范围内使用(所以这一访问级别有时也叫做“包装访问”) protected(受保护的):与“private”相似,只是一个继承的类就可以访问咱们的受保护成员,但是依旧不能访问私有成员。
方案的重复使用
创建并测试好一个类后,这个好不容易创建好的类其实往往有很多缺点。只有较多经验以及洞察力的人才能 设计出一个好的方案。
为了重复使用一个类,最简单的方法就是仅直接使用那个类的对象。同时也将那个类的一个对象植入一个新类中。我们把这叫做“创建一个成员对象”。新类可以由任意数量和类型的其他对象构成。这个概念叫做“组织”——在现有类的基础上组织一个新类。有时组织也称为“包含”关系,比如“一辆车包含了一个变速箱”
对象的组织具有极大的灵活性。新类的“成员对象”通常设为“私有”,使用这个类的使用者程序员不能访问它们。
继承:重新使用接口
当我们费尽心思做出一种数据类型之后,加入不得不又新建一种类型,令其实现大致相同的功能,那会是一件很麻烦的事情。但是若能利用已有的数据类型,对其进行“克隆模仿”,再根据实际情况进行添加或修改,那情况就会好多了。“继承”正是针对这个目标而设计的。但是继承并不完全等价于克隆。在继承的过程中,如果父类发生了变化,子类(继承后产生的新类)也会反映出这种变化。
在Java中继承是通过extends关键字实现的。使用继承时,相当于创建了一个新类。这个新类不仅包含了现有类型的所有成员(除了不能被访问的private成员)。其中最最重要的是它还复制了父类的接口。也就是说,能向父类发送的消息,亦可原样发给子类的对象。
由于父类和子类拥有相同的接口了,但是我们的子类不能一模一样呀,那样还跟父类有什么区别?为了做出区分,所以那个接口也必须进行特殊的设计。下面讲一下两种区分父类和子类的方法:
区分父类子类的方法
方法一:为子类添加新函数(功能)。这些新函数并非父类接口的一部分。为什么会有这种方法的出现呢?一般是因为我们发现父类原有的功能已经不能满足我们的需求了,于是我们就要添加更多的函数。这是一种最简单最基本的继承用法。
方法二:近看extends关键字看上去是让我们要为接口“扩展”新功能,但实情并非肯定得照办。为了区分我们的新类,第二个办法就是改变父类,“改善”父类。
改善父类
为了改善一个父类,我们无非就是改善父类中的函数(或者叫方法),那么我们相应的只需要在子类中的函数中建立一个新的定义就可以了。我们的目标是:”尽管使用的函数接口未变,但他的新版本具有不同的表现“,但是万物没有这么绝对,我们还有另外情况,这边引用两个概念:等价关系和类似关系
等价关系:子类完全照搬父类的所有的东西 类似关系:我们在子类中新加入了新的东西,那是原来父类中没有的东西。新的子类依旧拥有旧的父类的接口,但也包含了其他一些新的东西。所以就变成了不是上面所说的那种“等价关系”。
举一个例子:假定我有一个房间,房间连好了用于制冷的各种控制装置,用程序员思维来看,就是说我们已经拥有了必要的“接口”来控制制冷。现在假设我们的制冷机坏掉了,于是我将它换成了一台新型的冷、热两用空调,冬天制热、夏天制冷嘛。冷热空调“类似“制冷机,但是能做更多的事情。但是呢,由于我们的房间只安装了控制制冷的设备”接口“,所以”接口“们只能同新机器的制冷部分打交道。新机器的接口已得到扩展,但现有的系统并不知情,也不能够接触除了原始接口以外的任何东西。
当我们明确了等价和类似两种概念之后,以后在面对情况的时候就可以合理选择了。
多形对象的互换使用
继承的结果往往会是创造了一系列的类,而这所有的类都是建立在统一的接口基础上的。如图
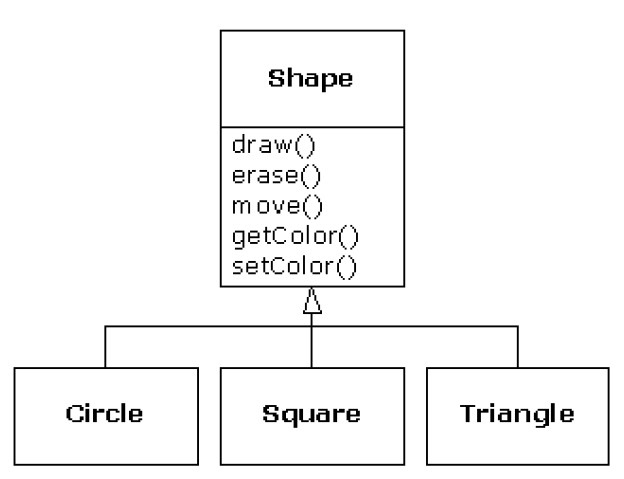
这边要讲一个很重要的概念了哈,我们一定要把子类的对象当做父类的对象来对待。这一点是非常重要的。这就意味着我们只需编写代码就行了,不需要注意类的特定细节,只与父类打交道。
根据图例我们可以看到通过集成,这边有三个子类。那么我们为三个子类新编写的代码也会像在父类中那样良好工作。所以说程序具备了“扩展能力”,具有扩展性。
假设我们新加了一个函数:
void doStuff(Shape s)}{
s.erase();
// 等等等等等
s.draw();
}
这样一个函数可以用途任何“几何形状”(Shape)通信,例如我这边又安排了一个代码:
Circle c = new Circle();
Triangle t = new Triangle();
Line l = new Line();
doStuff(c);
doStuff(t);
doStuff(l);
这边我就分析一下doStuff(c)这串代码的意思(事实就是:我确实后边安排了这个代码) 此时,一个Circle句柄传递给了一个本来期待Shape句柄的函数。但是由于咱们的圆也是一种几何形状,所以doStuff()能够正确地进行处理。也就是说,凡是doStuff()能发给一个Shape的消息,Circle也能接收。所以这样子写是正确的,不会有报错。
我们把这种生成子类的方法叫做向上转型。向上是因为继承的方向是从“上面”来的——即父类位于顶部,子类在下方展开。
注意了哦,doStuff()里面的代码,它并非是这样表达的:”如果你是一个Circle,就这样作;如果你是一个Square,就按照那样做;等等诸如此类“。若那样子写代码的话,得累死你,就需要检查Shape所有可能的类型,如圆、矩形、四边形等等等等。这显然是非常麻烦的,而且每次添加了一种新的Shape类型后,都要相应地进行修改,在这里,我们只需要这样做:”你是一种几何形状,我知道你能将自己删掉(即代码里面的erase()),请自己放手去干吧,并且自己去控制所有的细节吧。“
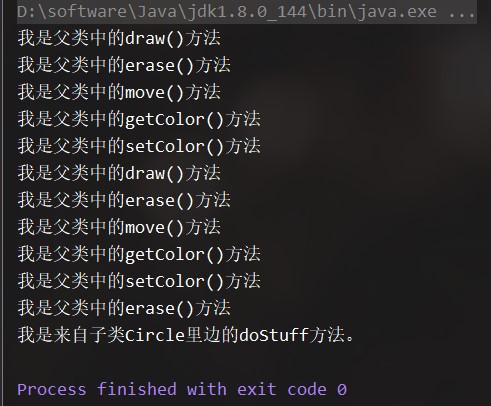
这边我写了三个代码有助于我们理解:
代码一(Shape父类):
package cn.mr8god.shape;
import static java.lang.System.*;
/**
* @author Mr8god
* @date 2020/4/1120:28
*/
public class Shape {
public void draw(){
out.println("我是父类中的draw()方法");
}
public void erase(){
out.println("我是父类中的erase()方法");
}
public void move(){
out.println("我是父类中的move()方法");
}
public void getColor(){
out.println("我是父类中的getColor()方法");
}
public void setColor(){
out.println("我是父类中的setColor()方法");
}
代码二(Circle继承类):
package cn.mr8god.shape;
import static java.lang.System.*;
/**
* @author Mr8god
* @date 2020/4/822:04
*/
public class Circle extends Shape{
void doStuff(Shape s){
s.erase();
out.println("我是来自子类Circle里边的doStuff方法。");
}
}
代码三(ShapeTest类):
package cn.mr8god.shape;
/**
* @ Mr8god
* @ 2020/4/11
*/
class ShapeTest {
public static void main(String[] args) {
Shape sh = new Shape();
sh.draw();
sh.erase();
sh.move();
sh.getColor();
sh.setColor();
Circle ci = new Circle();
ci.draw();
ci.erase();
ci.move();
ci.getColor();
ci.setColor();
ci.doStuff(ci);
}
}
自此输出:
如何实现控制访问
Java用三个关键字在类的内部设定边界:public、private、protected。这些访问指定词决定了紧跟其后被定义的东西可以被谁使用。
public:表示紧随其后的元素对任何人都是可用的
private:这个关键字表示除类型创建者和类型的内部方法之外的其他任何人都不能访问的元素。private就像你与使用类的程序员之间的一堵墙,如果有人试图访问private成员,就会在编译期间得到错误信息。
protected:这个关键字与private作用相当,差别仅在于继承的类可以访问protected成员,但是不能访问private成员。