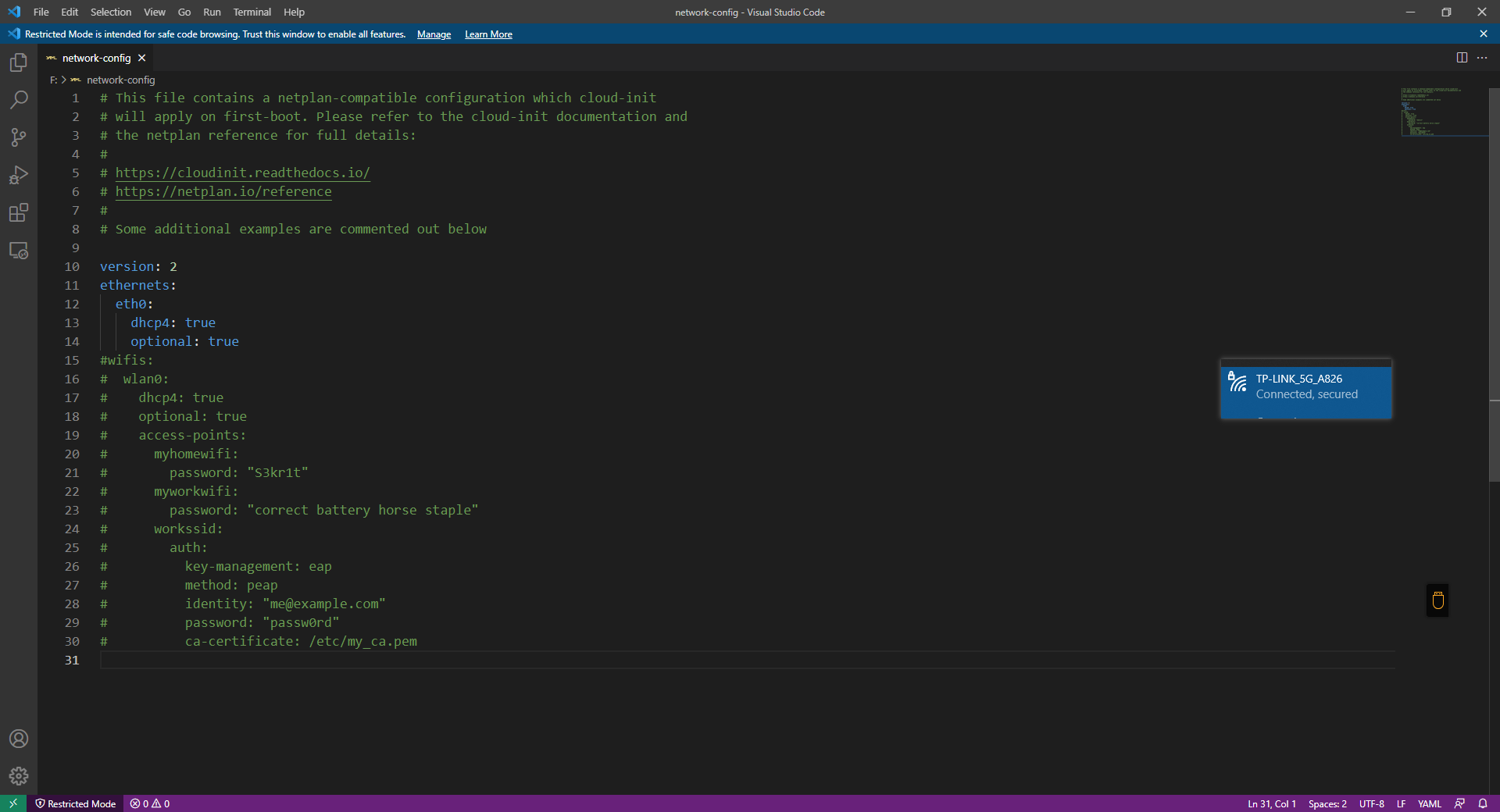
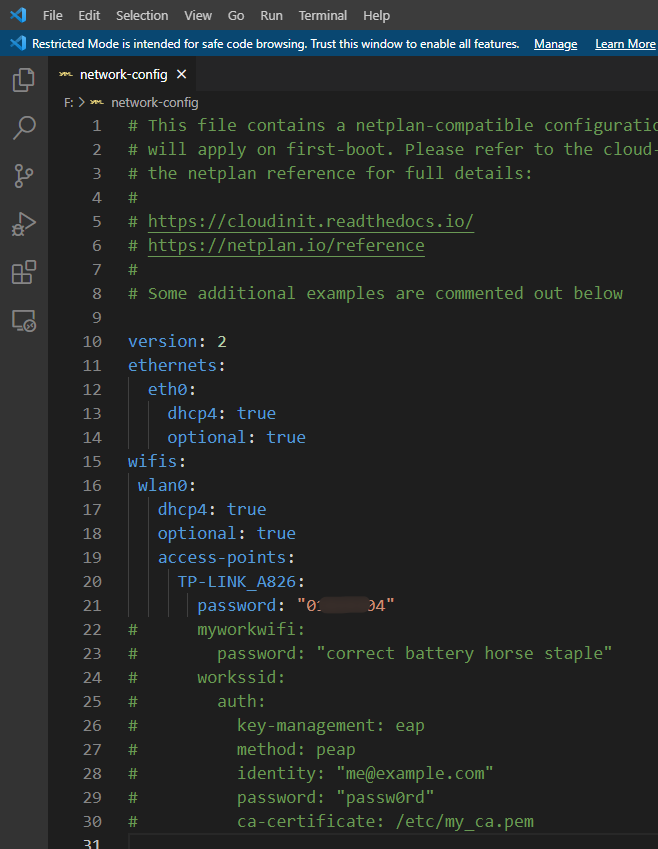
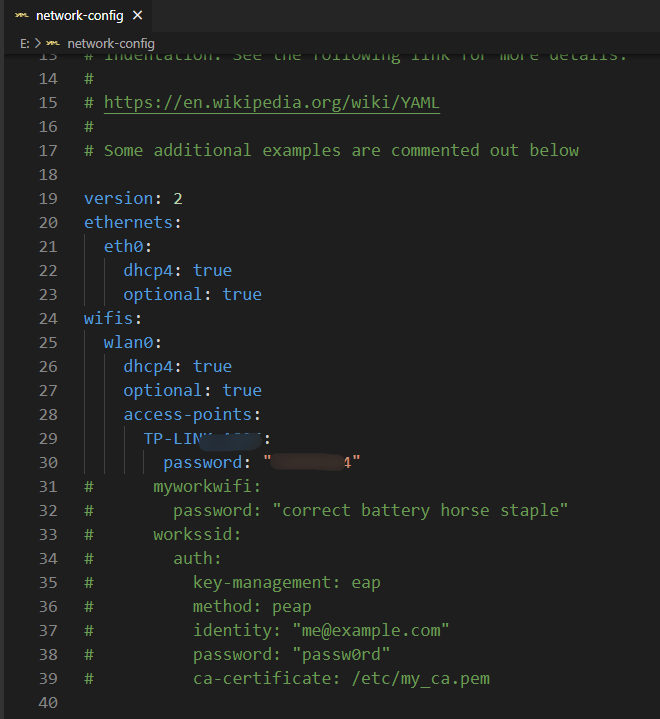
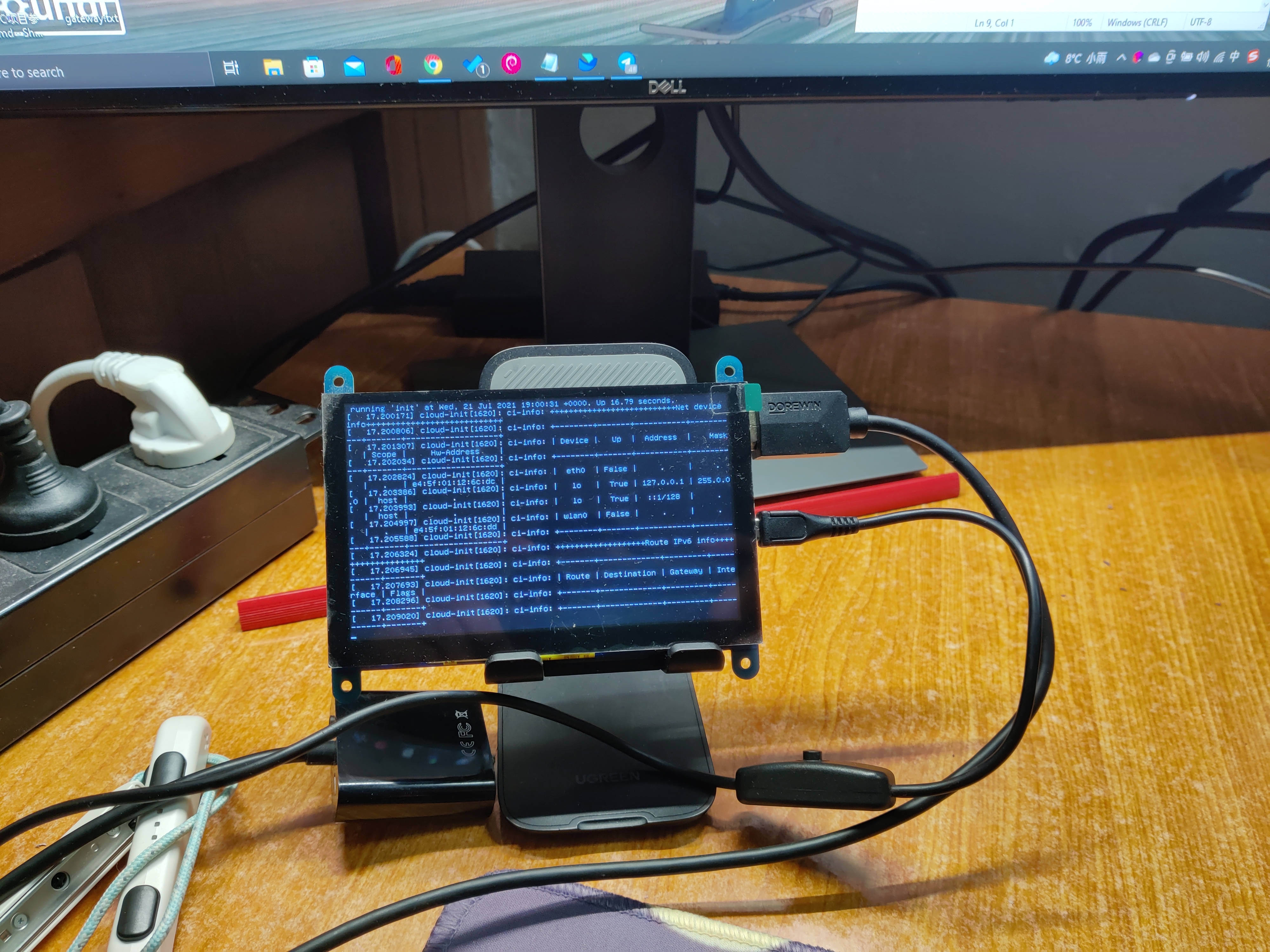
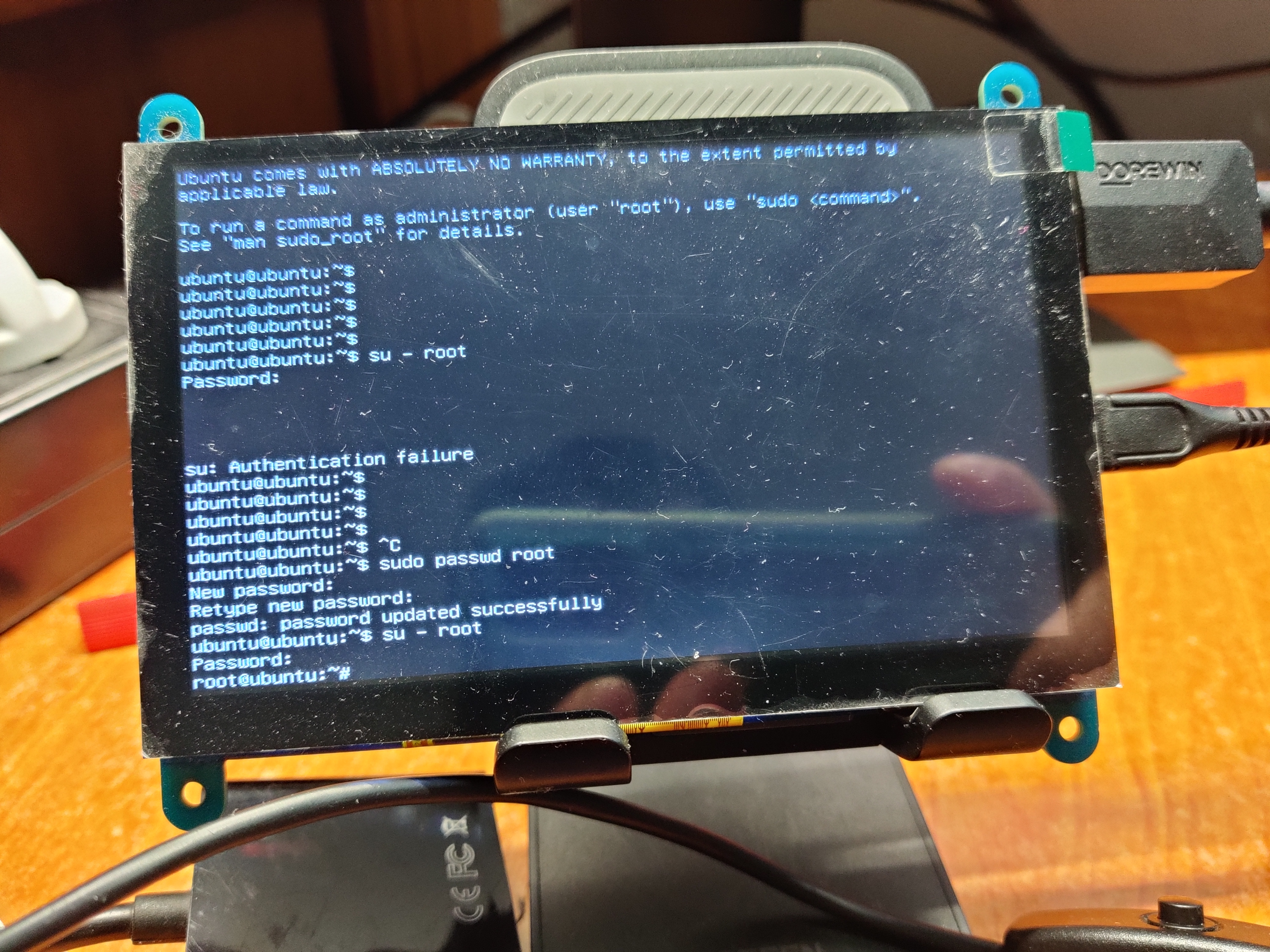
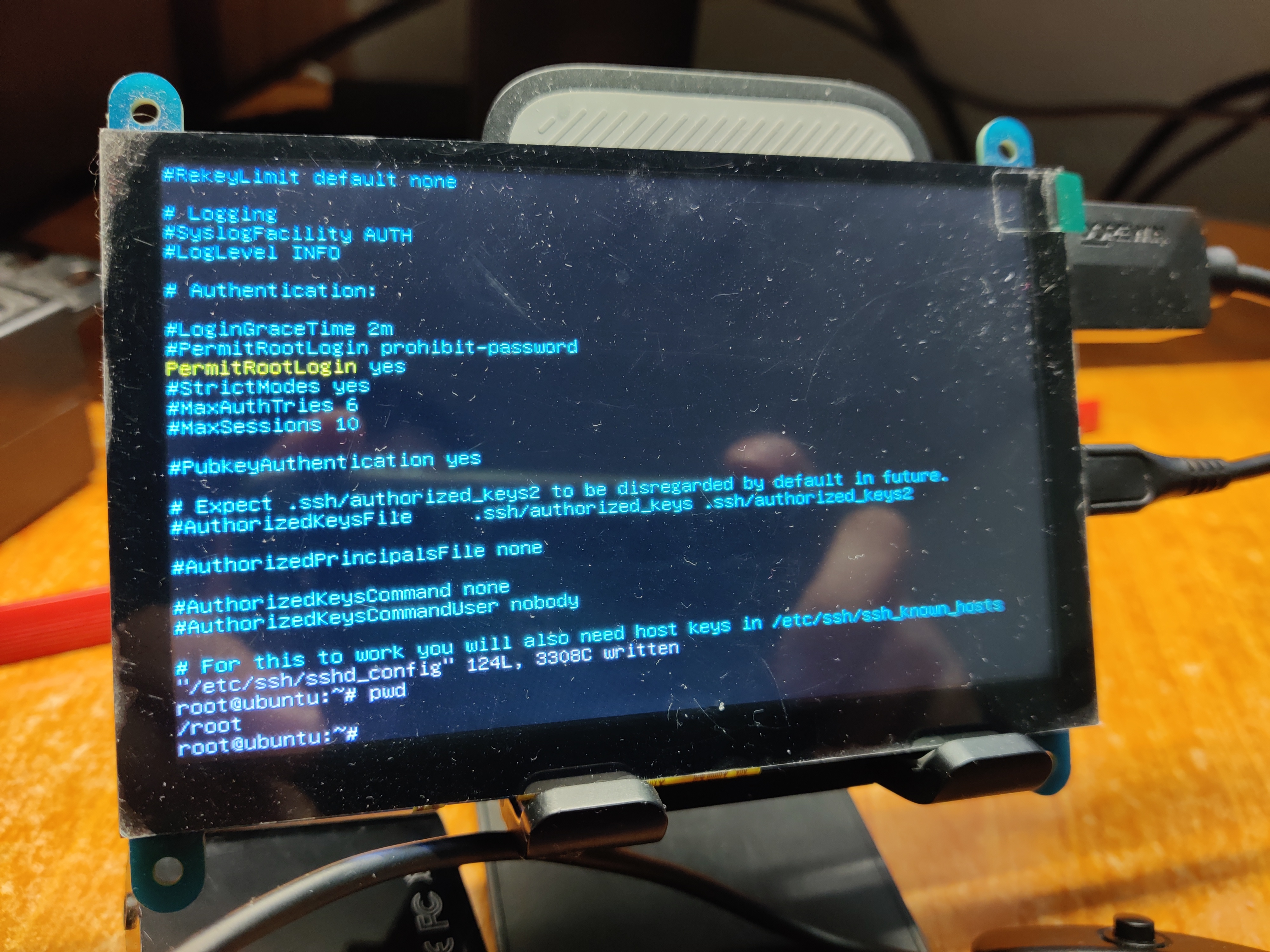
细节问题:没想到已经跑通测试的我,还是在新的开发机上跑测试框架遇到了问题。本次主要问题在于
一个安装包问题,所以说环境是真的无语,还是得设置到代理啊。我设置了git 的代理解决了问题,
详情方法,请参考 link ,我的主要疏忽在于,没注意端口,
因为之前实在 Windows 本上做开发的,用的是 v2ray,端口是 10808,没曾想就照着走错了,离谱啊。此处 mark 一下,需要注意。
然后还有一个点需要注意一下,make deps 和 LUAROCKS_SERVER=https://luarocks.cn make deps 可以混着用,over。
use whole request body to parse graphql will get parse error.
graphql request body is json , example :{"query":"query{getUser{name age}}","variables":null},
{"query": "query{ getUser{ name age } }", "variables":null }
-- -- Licensed to the Apache Software Foundation (ASF) under one or more -- contributor license agreements. See the NOTICE file distributed with -- this work for additional information regarding copyright ownership. -- The ASF licenses this file to You under the Apache License, Version 2.0 -- (the "License"); you may not use this file except in compliance with -- the License. You may obtain a copy of the License at -- -- http://www.apache.org/licenses/LICENSE-2.0 -- -- Unless required by applicable law or agreed to in writing, software -- distributed under the License is distributed on an "AS IS" BASIS, -- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -- See the License for the specific language governing permissions and -- limitations under the License. -- local core_str = require("apisix.core.string") local core_tab = require("apisix.core.table") local request = require("apisix.core.request") local log = require("apisix.core.log") local config_local = require("apisix.core.config_local") local tablepool = require("tablepool") local get_var = require("resty.ngxvar").fetch local get_request = require("resty.ngxvar").request local ck = require "resty.cookie" local gq_parse = require("graphql").parse local setmetatable = setmetatable local sub_str = string.sub local ngx = ngx local ngx_var = ngx.var local re_gsub = ngx.re.gsub local ipairs = ipairs local type = type local error = error local pcall = pcall local _M = {version = 0.2} local GRAPHQL_DEFAULT_MAX_SIZE = 1048576 -- 1MiB local function parse_graphql(ctx) local local_conf, err = config_local.local_conf() if not local_conf then return nil, "failed to get local conf: " .. err end local max_size = GRAPHQL_DEFAULT_MAX_SIZE local size = core_tab.try_read_attr(local_conf, "graphql", "max_size") if size then max_size = size end local body, err = request.get_body(max_size, ctx) if not body then return nil, "failed to read graphql body: " .. err end local ok, res = pcall(gq_parse, body) if not ok then return nil, "failed to parse graphql: " .. res .. " body: " .. body end if #res.definitions == 0 then return nil, "empty graphql: " .. body end return res end local function get_parsed_graphql() local ctx = ngx.ctx.api_ctx if ctx._graphql then return ctx._graphql end local res, err = parse_graphql(ctx) if not res then log.error(err) ctx._graphql = {} return ctx._graphql end if #res.definitions > 1 then log.warn("Multiple operations are not supported.", "Only the first one is handled") end local def = res.definitions[1] local fields = def.selectionSet.selections local root_fields = core_tab.new(#fields, 0) for i, f in ipairs(fields) do root_fields[i] = f.name.value end local name = "" if def.name and def.name.value then name = def.name.value end ctx._graphql = { name = name, operation = def.operation, root_fields = root_fields, } return ctx._graphql end do -- 获取特殊var的方法 local var_methods = { method = ngx.req.get_method, -- ref: https://github.com/cloudflare/lua-resty-cookie cookie = function () if ngx.var.http_cookie then return ck:new() end end } local no_cacheable_var_names = { -- var.args should not be cached as it can be changed via set_uri_args args = true, is_args = true, } local ngx_var_names = { upstream_scheme = true, upstream_host = true, upstream_upgrade = true, upstream_connection = true, upstream_uri = true, upstream_mirror_host = true, upstream_cache_zone = true, upstream_cache_zone_info = true, upstream_no_cache = true, upstream_cache_key = true, upstream_cache_bypass = true, var_x_forwarded_proto = true, } local mt = { -- 重载 hash 元方法 -- t 是 self __index = function(t, key) -- 若 cache table 存在直接返回 local cached = t._cache[key] if cached ~= nil then return cached end if type(key) ~= "string" then error("invalid argument, expect string value", 2) end local val -- 如果是特殊类型, 使用特定方法获取 local method = var_methods[key] if method then val = method() elseif core_str.has_prefix(key, "cookie_") then -- 通过 var_methods 访问到 resty.cookie local cookie = t.cookie if cookie then local err val, err = cookie:get(sub_str(key, 8)) if err then log.warn("failed to fetch cookie value by key: ", key, " error: ", err) end end elseif core_str.has_prefix(key, "arg_") then local arg_key = sub_str(key, 5) local args = request.get_uri_args()[arg_key] if args then if type(args) == "table" then val = args[1] else val = args end end elseif core_str.has_prefix(key, "http_") then key = key:lower() key = re_gsub(key, "-", "_", "jo") -- 最终通过 ngx.var 获取 val = get_var(key, t._request) elseif core_str.has_prefix(key, "graphql_") then -- trim the "graphql_" prefix key = sub_str(key, 9) val = get_parsed_graphql()[key] elseif key == "route_id" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.route_id elseif key == "service_id" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.service_id elseif key == "consumer_name" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.consumer_name elseif key == "route_name" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.route_name elseif key == "service_name" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.service_name elseif key == "balancer_ip" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.balancer_ip elseif key == "balancer_port" then val = ngx.ctx.api_ctx and ngx.ctx.api_ctx.balancer_port else val = get_var(key, t._request) end if val ~= nil and not no_cacheable_var_names[key] then t._cache[key] = val end return val end, __newindex = function(t, key, val) if ngx_var_names[key] then ngx_var[key] = val end -- log.info("key: ", key, " new val: ", val) t._cache[key] = val end, } function _M.set_vars_meta(ctx) local var = tablepool.fetch("ctx_var", 0, 32) if not var._cache then var._cache = {} end var._request = get_request() setmetatable(var, mt) ctx.var = var end function _M.release_vars(ctx) if ctx.var == nil then return end core_tab.clear(ctx.var._cache) tablepool.release("ctx_var", ctx.var, true) ctx.var = nil end end -- do return _M
server { listen 1980; access_log logs/access-1980.log main; error_log logs/error.log; location / { content_by_lua_block { ngx.header["Content-Type"] = "text/html" local headers = ngx.req.get_headers() ngx.say("---Headers") for k, v in pairs(headers) do ngx.say(k .. ":" .. v) end local args = ngx.req.get_uri_args() ngx.say("---Args") for k, v in pairs(args) do ngx.say(k .. ":" .. v) end ngx.say("---URI") ngx.say(ngx.var.uri) ngx.say("---Service Node") ngx.say("Ubuntu-DEV-1980") } } }
In computer networking and telecommunications, a gateway is a component that is part of two networks, which use different protocols. The gateway will translate one protocol into the other. A router is a special case of a gateway.
Gateways, also called protocol converters, can operate at any network layer. The activities of a gateway are more complex than that of the router or switch as it communicates using more than one protocol.
Both the computers of internet users that serve pages to users are host nodes. The nodes that connect the networks in between are gateways. These are gateway nodes:
the computers that control traffic between company networks